JavaScript is an amazing programming language and it’s the brain of the Web. However it’s also known to be “weird” or having “quirks” due to its unusual and sometimes unintuitive behavior.
In this article I’ll cover few JavaScript quirks related to strings. In order to understand how JavaScript works with strings, we first need to understand code points, code units, and surrogate pairs.
Code points
Code points are used to map a numerical value to a specific character. Think of code points as entries in a massive table that enables us to reference any possible character, or more precisely, any “grapheme.”
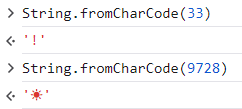
For example the codepoint 33 maps to the “!” symbol, while the codepoint 9728 maps to the “☀” symbol. In JavaScript, we can play with code points by using the String.fromCharCode() function:
Code units
JavaScript represents strings as sequences of UTF-16 code units. A code unit is the smallest storage used by an encoding system to represent a code point. Since JavaScript uses UTF-16, any code unit is 16 bit (2 bytes) wide. It means that a single code unit can represent at most 2^16 (65536) different code points (0x0000 - 0xFFFF).
However the Unicode system evolved during the years, and today (November 2024) is capable of encoding 154998 different characters. This means that we can’t encode many of these characters with just 16 bits.
Surrogate pairs
In order to overcome this issue, UTF-16 represents characters above 0xFFFF using something called surrogate pairs.
Basically a surrogate pair is a pair of special 16 bit codes that together are able to encode a single unicode code point grater than 0xFFFF.
There are 2 types of surrogates:
- high surrogates (in the range 0xD800 - 0xDBFF)
- low surrogates (in the range 0xDC00 - 0xDFFF)
The algorithm to get a UTF-16 representation of a code point higher than 0xFFFF is the following. Let’s say we want to encode the symbol “🔮” (code point 0x1F52E):
- Subtract the offset 0x10000 from our code point
- 0x1F52E - 0x10000 = 0xF52E
- Split the resulting 20 bits is 2 parts:
- 0xF52E in binary is 0000 1111 0101 0010 1110
- The top 10 bits maps to the high surrogate –> 0000 1111 01 = 0x3D
- The bottom 10 bits maps to the low surrogate –> 01 0010 1110 = 0x12E
- Add those values to high and low surrogates respectively:
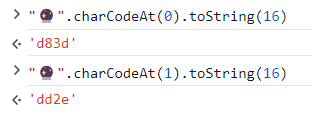
- 0xD800 + 0x3D = 0xD83D
- 0xDC00 + 0x12E = 0xDD2E
- The resulting UTF-16 representation is then the pair 0xD83D, 0xDD2E
We can confirm the result by using the charCodeAt() function as follows:
JavaScript quirks with strings
Now that we know the basics, can we explain the following behavior?
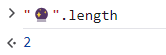
Even though “🔮” for a human being is a single character, it is represented as a pair of two code units (high and low surrogates) so the resulting length is 2!
This can already be an issue, for example imagine the following code:
// Server-side validation with the assumption that 1 character = 1 length
function validatePasswordLength(password) {
const minLength = 8;
if (password.length < minLength) {
throw new Error("Password is too short"); }
console.log("Valid password");
}
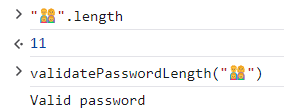
We could provide the password “👨👩👧👦” and we’ll pass the check, since "👨👩👧👦".length returns 11!
This happens because some emojis are actually a combination of multiple code points. We can check it by using the split() function:

Or we can check the single elements with the spread operator:

We can see that this emoji (the family emoji) is just a combination of several emojis. The empty strings are a special element called Zero Width Joiner (with code point 0x200D) which is used to combine adjacent elements (in this case: the men with the woman, the woman with the girl, the girl with the boy).
Things can be even worse. For example, let’s assume we have a naif (and pretty weak) validation function that removes “<” characters from a user controlled string, in order to prevent Cross-Site Scripting. Of course this is not enough to protect against XSS, but it’s just to show how UTF-16 strings in JavaScript can have unwanted and potentially dangerous behavior.
The function removeForbiddenCharacter is defined as follow:
function removeForbiddenCharacter(input) {
let result = input; // Start with the original string
let index = 0; // Start from index 0
// Loop through each character of the input string
for(const char of input) {
if(char === '<'){
// Use slice to remove the "<" character
result = result.slice(0, index) + result.slice(index + 1);
}
else{
index++;
}
}
return result;
}
And it works as expected when the input is a regular string:

However, if we provide an emoji just before the forbidden character, we are able to bypass the validation and we can successfully inject JavaScript code:

This is possible because the (bad) implementation of the removeForbiddenCharacter doesn’t take into account the fact that when the if condition is true (index is pointing to the forbidden character, which in this case is the 10th starting from 0) the slice operations will remove the low surrogate component instead of the actual “<” character (we can see the the high surrogate component 0xD83D is still there), because the 10th code unit doesn’t correspond to the 10th actual character of the string. The following image shows what is happening:
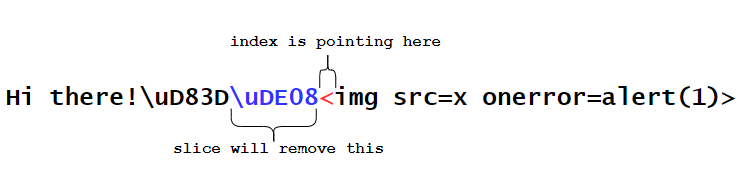
This was merely a fictional and artificial example, unlikely to be encountered in real-world scenarios. However, similar issues related to JavaScript and string manipulation have been identified and reported in popular bug bounty programs, such as this one on GitHub or this one on Swisscom . Furthermore, someone already implemented a UTF-safe library that can be used to avoid such issues.
Conclusion
As we saw, JavaScript’s handling of strings and UTF-16 can lead to unexpected behaviors due to its quirks and peculiarities. These quirks can lead to security vulnerabilities, such as bypassing input validation or causing incorrect behavior in applications. Developers must be aware of these things to avoid subtle bugs and ensure robust, secure code, especially when dealing with complex Unicode characters or performing string-based operations.