Some days ago I came across this interesting article from AT&T: we have an analysis about a “new” (September 2022) Linux malware named Shikitega.
The analysis is very interesting and I decided to use it as an exercise to create a new Yara rule to detect it (in a while I’ll also explain you why I’m interested in Yara rules in these days :-)).
Oh, and just in case, if you don’t know what a Yara rule is, you can get a quick intro here.
Analysis
The original analysis made by AT&T says a lot, but I’d like to have a look personally to the files mentioned there, so I started collecting some of the samples:
b9db845097bbf1d2e3b2c0a4a7ca93b0dc80a8c9e8dbbc3d09ef77590c13d331
0233dcf6417ab33b48e7b54878893800d268b9b6e5ca6ad852693174226e3bed
f7f105c0c669771daa6b469de9f99596647759d9dd16d0620be90005992128eb
8462d0d14c4186978715ad5fa90cbb679c8ff7995bcefa6f9e11b16e5ad63732
All of these are very small ELF executables, so the analysis is quite straightforward.
Sample #1
Let’s have a look to the first one. Open up Ghidra and we see the following:
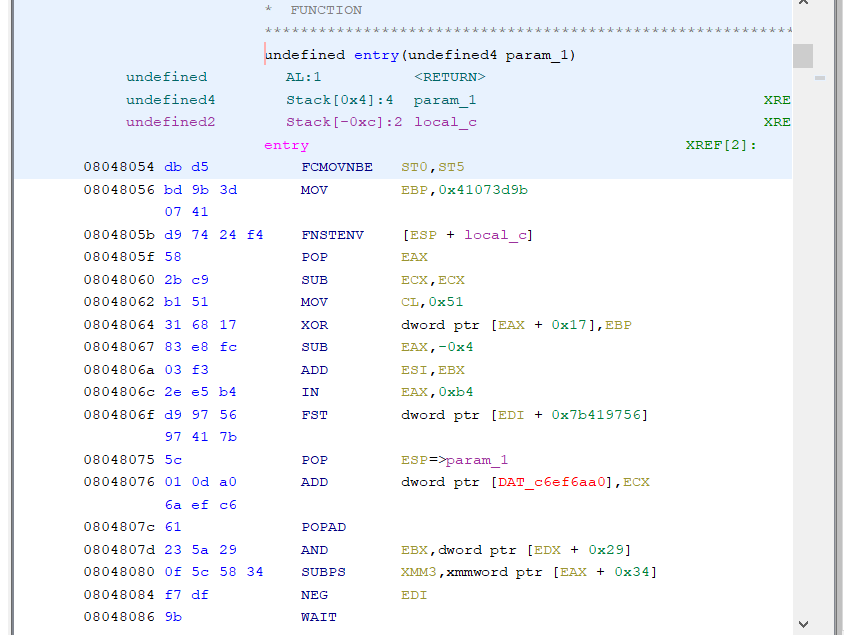
If you are used to the payloads created by meterpreter utility, and in particular to the Shikata-ga-nai encoder, I think you will find this quite familiar. This is very similar to the common stub used to start the decoding of the payload.
Looking at the instructions we see the XOR key used (0x41073bd9) and then the start of the decoding loop. As you can see in this case the position of the code in memory is found by using the FNSTENV FPU instruction. So far so good.
Sample #2
Now we can open the second sample:

Very similar situation here: a different XOR key is used (0xa7bc0447), but the rest of the stub is pretty much the same. Again, same FPU instruction used to the the EIP.
Sample #3
Third sample:
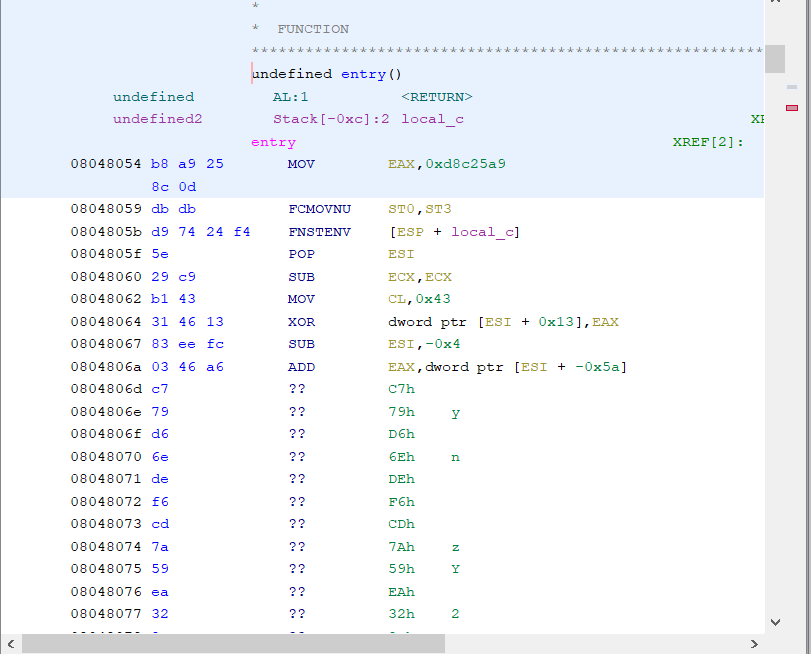
Everything look pretty consistent: a different key again, but same technique for EIP (with a different register in this case, but not a problem).
I examined some additional samples, and all were more or less done in the same way.
The Yara rule
So, we identified some common features of the samples and we can start in developing our rule.
We can summarize that:
- file must be an ELF file
- size is pretty small (<2KB)
- we can search for the specific
FNSTENVinstruction (which is present in all the samples), in a specific range of the file
I ended up with something like this:
rule Linux_Sorint_shikitega_dropper {
meta:
author = "Sorint.lab"
strings:
$fnstenv = { D9 74 24 F4 }
condition:
filesize < 2KB and uint32(0) == 0x464c457f and $fnstenv in (64..128)
}
Performance
Now that I created the Yara rule, I was thinking about performance. Is this rule good enough?
As a first step I reviewed this article from Florian Roth: this is full of very good advice.
Then I found, from the same author, a script which allow to evaluate the performance of a rule or of a set of rules:
The usage of the tool is pretty easy: it expects a set of samples in input. This set should be as close as possible to the real target of the rule you want to test: if you plan to use it on specific file types, you should provide that. Otherwise just choose a wide selection of files.
Then you have to provide your rule. The tool will create a baseline with an internal set of rules and then it will add your, in order to evaluate the impact.
Let’s try…
In order to have consistent runs, the site suggest to run it with specific priority and affinity (may be you need to sudo)
chrt -r 99 taskset -c 7 ./panopticon.py
Then I provided some samples in the samples folder. The site suggest 50-100MB of data. I started putting 100MB of executables from the /bin/ folder.
Run #1
[INFO ] Calibrations done, now checking the rules
[WARNING] Rule "Linux_Sorint_shikitega_dropper" slows down a search with 50 rules by 6.3859 % (Measured by best of 34 runs)
That’s bad! My rule seems to be a little crappy. Back to the drawing board.
Run #2
Snooping around I noticed that the check for the ELF file is often done by comparing the first 2 bytes, instead of 4. So, I tried to modify the rule with uint16(0) == 0x457f
[INFO ] Rule "Linux_Sorint_shikitega_dropper" is fast enough, not measuring any further due to fast mode, diff 1.0459 % below alerting level: 3.2756 %
OK, big improvement! Not so bad at the end!
Run #3
The rule seems to be usable now, but I’d like to experiment a bit more. The samples I provided are not probably very realistic: scanned folders (in my use case) are probably composed by mixed files, not only executables. So I created a new mixed samples folder and tried again:
[INFO ] Rule "Linux_Sorint_shikitega_dropper" is fast enough, not measuring any further due to fast mode, diff 1.8619 % below alerting level: 3.0000 %
With the more realistic samples seems a bit slower, but still under the alerting level.
Run #4
Instead of using Fast mode, I want to try the Slow one, by adding -S option:
[INFO ] Rule: "Linux_Sorint_shikitega_dropper" - Best of 75 - duration: 0.4065 s (0.0046 s, 1.1325 %)
% dropped a bit, more close to the Run #2.
Run #5
I want to try an additional thing: I want to remove the filesize option, to see the effect:
[INFO ] Rule: "Linux_Sorint_shikitega_dropper" - Best of 75 - duration: 0.4079 s (0.0054 s, 1.3315 %)
Now execution time increased a bit, so filesize seems to be useful in this case, even if variation in this case is very small.
Run #6
The little difference on the last run left me some doubts, I think there is something I’m missing.
By carefully reading again the “Performance Guidelines” mentioned above, there is an important part:
After all pattern matching is done, the conditions are checked.
This could explain why adding filezise condition didn’t make a big difference: pattern matching is done anyway, also on very big files.
So I started to look around to find a solution to this. Reading docs I stumbled on private rules:
They are just rules that are not reported by YARA when they match on a given file
Nice. So may be that combining this rule with my previous one I can improve the performance even more. Let’s try to re-write the rule in the following way:
private rule PreFilter_shikitega {
condition:
filesize < 2KB and uint16(0) == 0x457f
}
rule Linux_Sorint_shikitega_dropper {
meta:
author = "Sorint.lab"
strings:
$fnstenv = { D9 74 24 F4 }
condition:
PreFilter_shikitega and $fnstenv in (64..128)
}
Another run of Panopticon
Rule: "PreFilter_shikitega" - Best of 75 - duration: 0.4049 s (0.0031 s, 0.7608 %)
Now the difference is a bit more significant. In this case the matched rule is the PreFilter, which make sense since I don’t have any file in the samples matching the conditions in PreFilter.
But there is even something more: I see an error in the Panopticon log which says
Error compiling YARA rule 'Linux_Sorint_shikitega_dropper' : line 1106: undefined identifier "PreFilter_shikitega"
Probably Panopticon evaluates each rule by its own and you can not refer to another one (at least this is my take on this). In our case it should not be a big issue for our evaluation (since the one matching more times is the PreFilter), but it’s something to keep into consideration.
Conclusions
The very first version of the rule was not performing very well, even if probably the sample folder composed only by executable files may be put more stress on the ELF file recognition.
It’s pretty clear that writing a good Yara rule is not an easy task! You need to take into consideration a lot of things:
-
understand the basics of the Yara engine
-
choose the right criteria used to detect your target
-
choose the proper way to implement the criteria
-
think about the real use case, when the Yara rule will be deployed
Then tools came to help!