Semgrep is a powerful SAST tool that performs source code analysis in order to identify vulnerabilities.
In this article we’ll see how we can write simple but effective custom semgrep rules to prevent security bugs in your code.
But let’s first introduce the Abstract Syntax Tree and why it’s related to SAST tools.
SAST tools and Abstract Syntax Tree
SAST (Static Analysis Security Testing) is a technique that analyzes source code looking for vulnerable patterns. This allow us to identify possible security issues before deploying the application in production, hence reducing the risks of introducing vulnerabilities in our application.
SAST tools usually work on Abstract Syntax Tree (AST): the AST is a tree that represents the syntactic structure of the source code. It parses the source code and outputs a tree data structure that represents the actual semantic of the source code, abstracting away syntax.
For example, let’s say we have the following expression:
x = 1 + (y * 2)
We can represent it with the following (simplified) AST:
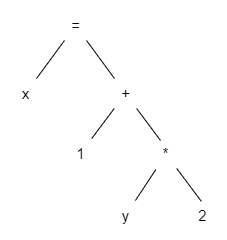
Of course, in real life, computers need to represent the AST in a more formal and structured way. We can use tree-sitter to see how a real AST looks like.
Let’s consider the following simple Java class:
public class Main {
int x = 5;
public static void main(String[] args) {
Main myObj = new Main();
System.out.println(myObj.x);
}
}
And let’s parse it using tree-sitter. This is what we get:
(program [0, 0] - [8, 0]
(class_declaration [0, 0] - [7, 1]
(modifiers [0, 0] - [0, 6])
name: (identifier [0, 13] - [0, 17])
body: (class_body [0, 18] - [7, 1]
(field_declaration [1, 2] - [1, 12]
type: (integral_type [1, 2] - [1, 5])
declarator: (variable_declarator [1, 6] - [1, 11]
name: (identifier [1, 6] - [1, 7])
value: (decimal_integer_literal [1, 10] - [1, 11])))
(method_declaration [3, 2] - [6, 3]
(modifiers [3, 2] - [3, 15])
type: (void_type [3, 16] - [3, 20])
name: (identifier [3, 21] - [3, 25])
parameters: (formal_parameters [3, 25] - [3, 40]
(formal_parameter [3, 26] - [3, 39]
type: (array_type [3, 26] - [3, 34]
element: (type_identifier [3, 26] - [3, 32])
dimensions: (dimensions [3, 32] - [3, 34]))
name: (identifier [3, 35] - [3, 39])))
body: (block [3, 41] - [6, 3]
(local_variable_declaration [4, 4] - [4, 28]
type: (type_identifier [4, 4] - [4, 8])
declarator: (variable_declarator [4, 9] - [4, 27]
name: (identifier [4, 9] - [4, 14])
value: (object_creation_expression [4, 17] - [4, 27]
type: (type_identifier [4, 21] - [4, 25])
arguments: (argument_list [4, 25] - [4, 27]))))
(expression_statement [5, 4] - [5, 32]
(method_invocation [5, 4] - [5, 31]
object: (field_access [5, 4] - [5, 14]
object: (identifier [5, 4] - [5, 10])
field: (identifier [5, 11] - [5, 14]))
name: (identifier [5, 15] - [5, 22])
arguments: (argument_list [5, 22] - [5, 31]
(field_access [5, 23] - [5, 30]
object: (identifier [5, 23] - [5, 28])
field: (identifier [5, 29] - [5, 30]))))))))))
So we can see that an AST of a simple Java class includes a lot of information. Actually, tree-sitter built what is called Concrete Syntax Tree (CST or also known as “parse tree”) which includes additional information related to the syntax of the language. Notice how tree-sitter was able to identify and track the exact line and column numbers for each node of the tree (they are specified between the square brackets []).
Also, tree-sitter is really powerful because it could parse any programming language, as long as there is a grammar that describes the language.
AST are widely used in different applications:
- compilers uses AST as an intermediate representation of the program which is then converted to a binary executable (specific for the CPU architecture)
- advanced text editors and IDEs uses AST to highlight the source code and to perform other complex operations (for example the ability of select specific blocks of code using shortkeys)
- source code analysis tools (like SAST, code linter, etc..) use AST to quickly parse the source code and look for specific patterns
SAST tools can leverage this formal representation of the source code, to perform static analysis and apply complex checks to detect suspicious and problematic patterns.
Semgrep uses (also) tree-sitter to get the CST and then translates it to the AST (using a custom parser) which is then used to match patterns defined by rules.
Now let’s see how we can write our first simple rule using the Semgrep engine.
Matching Spring unauthenticated routes using custom semgrep rule
Semgrep includes a public registry of rules which covers a lot of programming languages. So you can immediately start using them and scan your project to identify possible security issues.
But an interesting feature of semgrep, is that anyone can create custom rules. Furthermore, creating custom rules is fairly easy as it doesn’t require to know a specific programming language, as they are defined by simple YAML files.
Now, let’s say we are developing a Java application using Spring MVC framework. Let’s assume that the team agreed on using Java Spring annotations (and Spring Security) to perform authorization checks for each route exposed by the application.
For example let’s say we have the following REST controller which exposes few endpoints:
@RestController
public class UserController {
@Autowired
UserService userService;
@GetMapping("/users")
@PreAuthorize("hasRole('ADMIN')")
public ResponseEntity<List<User>> getAll() {
return new ResponseEntity<>(userService.getAll(), HttpStatus.OK);
}
@GetMapping("/users/{id}")
@PreAuthorize("hasRole('USER')")
public ResponseEntity<User> getById(@PathVariable long id) {
Object principal = SecurityContextHolder.getContext().getAuthentication().getPrincipal();
if (principal instanceof MyUserDetails) {
long userId = ((MyUserDetails)principal).getId();
// If current user `id` is not equal to the `id` parameter return forbidden error
if(!userId.equals(id)){
throw new ResponseStatusException(HttpStatus.FORBIDDEN);
}
} else {
throw new ResponseStatusException(HttpStatus.FORBIDDEN);
}
Optional<User> user = userService.getById(id);
if (user.isPresent()) {
return new ResponseEntity<>(user.get(), HttpStatus.OK);
} else {
throw new RecordNotFoundException();
}
}
}
The previous controller looks safe. We are using the @PreAuthorize annotation to achieve the following:
- Only users with
ADMINrole can get all users information - Only users with
USERrole can get their own details
Now let’s imagine someone (maybe a new junior developer who just joined the team, with lack of experience) is implementing a new features that should allow only the administrator to delete a user.
This would require to add another handler to the UserController (this time using @DeleteMapping annotation) as follows:
@DeleteMapping("/users/{id}")
public ResponseEntity<List<User>> deleteUser(@PathVariable long id) {
Optional<User> user = userService.getById(id);
if (user.isPresent()) {
userService.deleteUser(id);
return new ResponseEntity<>("User has been deleted!", HttpStatus.OK);
} else {
throw new RecordNotFoundException();
}
}
Unfortunately, the new route /users/{id} does not specify any authorization check (the @PreAuthorize() annotation is missing) so anyone (including unauthenticated users) would be able to delete any user. This is of course a trivial error and it could be detected manually, but imagine if you have hundreds of controllers, each one with hundreds of routes: it will be impractical (if not impossible) to detect the issue by looking at them manually.
Instead, using the following semgrep custom rule, we can easily detect such issues and prevent the vulnerable code to be deployed in our application:
rules:
- id: spring-unauthenticated-route
patterns:
- pattern-inside: |
@RestController
class $CONTROLLER{
...
}
- pattern-inside: |
@$MAPPING($ROUTE)
$RET $METHOD(...) {...}
- metavariable-regex:
metavariable: $MAPPING
regex: (GetMapping|PostMapping|DeleteMapping|PutMapping|PatchMapping)
- pattern-not: |
@PreAuthorize(...)
$METHOD(...){...}
- focus-metavariable:
- $ROUTE
message: >
The route $ROUTE is exposed to unauthenticated users. Please verify
this is expected behaviour, otherwise add the proper authentication/authorization checks.
languages:
- java
severity: WARNING
Let’s go through the rule step by step:
-
First we defined an
id: this is just a unique identifier for the rule. -
Then we have the
patternsoperator: this is the most important part of the rule, because it defines which patterns we want to match. Every child node of thepatternsoperator must be true in order to get a match (it acts as the logicANDoperator). -
The
pattern-insideoperator matches findings that reside within its expression. Since we are interested in Spring RestController classes we can use thepattern-insideto only match classes with the@RestControllerannotation. Notice that since we want to match any controller class (and we don’t know the class name in advance) we are using the$CONTROLLERmetavariable. In semgrep, a metavariable is an abstraction to match something that you don’t know the value yet (similar to capture groups in regular expressions). We can declare a metavariable by prepending the$sign to a variable name of our choice (it must be uppercase). -
Another
pattern-insideis used: in this case we want to match all the methods that have the annotation@$MAPPING. Basically this is another metavariable used to match all the Spring annotation that map some HTTP request to the method. Since the HTTP request can have different HTTP methods, we want to match all of them, so we can use themetavariable-regexoperator to define our regex. This is simply a regex expression to match one of the available mapping annotation provided by Spring (in this case(GetMapping|PostMapping|DeleteMapping|PutMapping|PatchMapping)) . Notice that in this pattern we are also using a special operator...called ellipsis: this is used to abstract away a sequence of zero or more items. Basically we are saying that we are not interested in the method arguments or in the method body. -
Then we use the
pattern-notoperator: since our goal is to match routes that are missing the authorization check, we can use this operator to find code that does not match this expression (hence it is missing the authorization check). -
Finally we use the
focus-metavariablejust to highlight the routes that matched our pattern (the ones that are missing the@PreAuthorizeannotation). -
The other fields (
message,languagesandseverity) are just metadata that is used by semgrep to provide info about the findings. Notice that we can refer to metavariables inside the message: the metavariable will be resolved automatically by semgrep when there is a match.
You can try and play with this rule using the semprep playground here. Just click on the “Run” button or press “Ctrl-Enter” to run the rule against the code on the right side of the screen. You should see 1 match at line 38, as shown below:
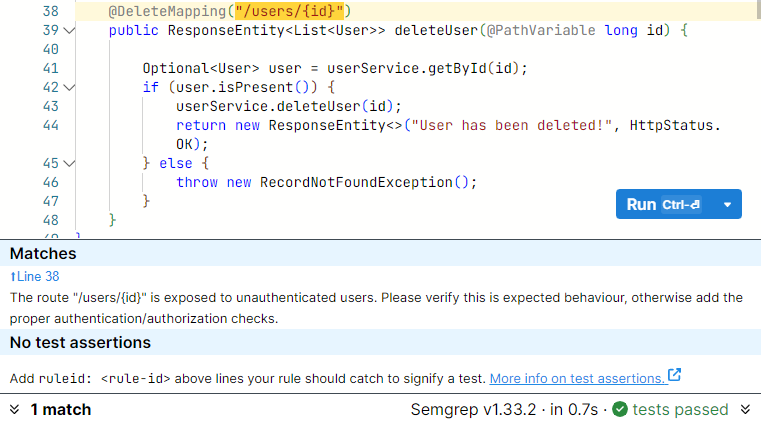
If you want to test your semgrep skills, try to modify the rule to:
- match also when using the generic
@RequestMapping(...)annotation - match only routes that are available to users with
ADMINrole
Conclusion
This was just a brief introduction to semgrep, a really powerful tool. There are a lot of more complex operators and techniques available (i.e. taint mode, autofix, etc..) so I’d encourage you to read the official documentation.
If you want to learn more about semgrep and create more advanced rules, I’d suggest to start practicing the semgrep tutorial.
You can even contribute by publishing your rules to the public semgrep-rules GitHub repository and help other developers to write more secure code!